Qu'est-ce que le Chain-of-Thought Prompting ?
Le Chain-of-Thought Prompting, souvent abrégé en CoT, est une méthode innovante qui transforme la façon dont les modèles d'intelligence artificielle, en particulier les grands modèles de langage (LLM), résolvent des problèmes complexes.
Cette technique permet de guider l'IA à travers une série d'étapes logiques et structurées, améliorant ainsi la précision et la cohérence des réponses fournies. Pour bien comprendre l'importance du Chain-of-Thought, il est essentiel de savoir comment les modèles de langage fonctionnent lorsqu'ils doivent raisonner de manière plus profonde.
Les grands modèles de langage, comme GPT-4, sont capables de générer du texte de manière fluide en se basant sur une vaste quantité de données préalablement ingérées. Toutefois, lorsqu'il s'agit de répondre à des questions ou de résoudre des problèmes nécessitant plusieurs étapes de raisonnement, ces modèles peuvent être limités. Par défaut, un modèle répond souvent de manière directe sans décomposer le processus en étapes, ce qui peut aboutir à des erreurs ou à des réponses incomplètes.
C'est là qu'intervient le Chain-of-Thought : il permet d'améliorer le raisonnement du modèle en le forçant à diviser sa réflexion en plusieurs phases successives.
Imaginons que vous souhaitiez enseigner à un enfant comment résoudre un problème mathématique complexe. Plutôt que de simplement donner la réponse finale, vous lui montreriez chaque étape de la résolution : comprendre la question, décomposer les données, appliquer les bonnes opérations, puis vérifier le résultat. Le Chain-of-Thought fonctionne de manière similaire pour les modèles d'IA, en les incitant à suivre une logique séquentielle plutôt que de deviner directement la solution.
En parcourant cet article, vous comprendrez non seulement les fondements de cette méthode, mais aussi pourquoi elle est cruciale pour tirer pleinement parti des modèles d'IA modernes, en les rendant plus fiables et plus transparents dans leurs réponses.
En effet, le Chain-of-Thought ne se contente pas de renforcer la précision des modèles ; il améliore également la transparence. En offrant une vue d'ensemble des étapes logiques suivies par le modèle, cette approche permet aux utilisateurs de mieux comprendre pourquoi et comment une certaine réponse a été générée. Cela s'avère particulièrement utile dans des contextes sensibles où la compréhension des raisonnements sous-jacents est nécessaire pour garantir la fiabilité des résultats.
Que vous soyez déjà familier avec le prompt engineering ou que vous soyez un novice en la matière, cet article vous donnera les clés pour comprendre pourquoi cette méthode est aujourd'hui l'une des plus prometteuses dans le domaine de l'IA.
Origine et Concepts Clés
Le concept de Chain-of-Thought a émergé des recherches visant à surmonter les limitations des grands modèles de langage (LLM) lorsqu'ils doivent effectuer un raisonnement complexe. Les premiers travaux sur cette approche ont démontré que, malgré leur puissance et leur capacité à traiter des quantités massives de données, les LLM avaient souvent du mal à suivre des étapes de réflexion structurées sans assistance explicite.
L'idée de Chain-of-Thought est donc née pour remédier à cette limitation, en permettant aux modèles de langage de diviser un problème en une série d'étapes logiques plus faciles à gérer.
Cette technique a été mise en avant pour la première fois dans des publications académiques qui ont exploré comment les modèles pouvaient bénéficier d'un guidage séquentiel. Une étude clé qui a popularisé cette méthode est disponible sur le site arXiv .
Dans cette étude, les chercheurs ont démontré que le fait de décomposer les tâches complexes en étapes successives permettait non seulement d'améliorer la précision des réponses, mais également de mieux comprendre la logique suivie par le modèle.
Le Chain-of-Thought se base sur une approche itérative, où chaque étape de raisonnement est explicitée avant de passer à la suivante. Ce type de méthodologie est particulièrement utile lorsque les modèles doivent traiter des tâches arithmétiques, logiques ou toute autre tâche nécessitant un enchaînement de réflexions.
En pratique, cela revient à fournir des indications claires au modèle sur la manière dont il doit aborder le problème, un peu comme un enseignant qui guide pas à pas un élève dans la résolution d'un exercice.
Les concepts clés du Chain-of-Thought incluent la décomposition des tâches, la séquentialité du raisonnement et l'explicitation des différentes phases de la résolution. Ces principes sont essentiels pour maximiser l'efficacité des modèles de langage, notamment dans des contextes dans lesquels la précision et la transparence sont cruciales.
En utilisant le Chain-of-Thought, les utilisateurs peuvent non seulement améliorer la qualité des réponses générées par les modèles, mais aussi avoir une meilleure compréhension des mécanismes qui ont conduit à ces réponses, ce qui est fondamental dans des domaines tels que la recherche scientifique, l'éducation et la gestion de projets complexes.
Types de Chain of Thought
Le Chain-of-Thought n'est pas une approche unique ; il existe plusieurs variantes qui permettent de répondre à des besoins spécifiques, en fonction du contexte et des objectifs de la tâche à accomplir.
Parmi ces variantes, deux des plus populaires sont le "Zero-shot CoT" et le "Few-shot CoT". Ces deux approches se distinguent par leur manière de fournir des indications aux modèles de langage.
Zero-shot Chain of Thought (Zero-shot CoT)
Le Zero-shot Chain-of-Thought est une méthode où le modèle de langage est incité à suivre une série d'étapes de raisonnement sans qu'aucun exemple spécifique ne soit donné au préalable. Autrement dit, le modèle est directement invité à élaborer une réponse de manière logique et détaillée, sans être explicitement entraîné avec des exemples qui illustrent ce raisonnement particulier.
Le Zero-shot CoT repose sur la capacité intrinsèque du modèle à raisonner de manière cohérente lorsque des instructions appropriées lui sont fournies. Cette approche est particulièrement utile pour les situations où l'on souhaite vérifier l'aptitude générale d'un modèle à raisonner sans guidage explicite.
Un exemple simple serait de demander à un modèle :
"Explique pourquoi les feuilles changent de couleur en automne ?"
Le modèle est alors invité à décomposer sa réponse en étapes logiques sans avoir été exposé à des exemples similaires auparavant. Bien que cette méthode soit intéressante pour évaluer la capacité d'un modèle à raisonner de manière autonome, elle peut parfois manquer de précision comparativement à des approches plus guidées.
Few-shot Chain of Thought (Few-shot CoT)
Vous l'aurez sûrement deviné, le Few-shot Chain-of-Thought consiste à fournir au modèle des exemples de raisonnement avant de lui demander de répondre à une nouvelle question.
 Source : arxiv.org
Source : arxiv.org
Ces exemples, appelés "prompts d'apprentissage", montrent au modèle comment décomposer une tâche en étapes successives. En utilisant ces exemples, le modèle est en mesure d'imiter la logique suivie dans les prompts et de l'appliquer à de nouvelles questions ou problèmes.
Cette approche permet généralement d'améliorer la qualité et la précision des réponses, car le modèle bénéficie d'une démonstration préalable du type de raisonnement attendu.
Par exemple, on pourrait fournir au modèle une série d'exemples comme : "Si tu veux déterminer le montant total des dépenses, commence par additionner les montants individuels, puis vérifie s'il y a des frais supplémentaires à inclure."
Une fois ces exemples fournis, le modèle sera plus à même de reproduire un raisonnement similaire lorsqu'il se voit poser une nouvelle question complexe. Le Few-shot CoT est particulièrement puissant dans des contextes où une grande précision est requise, car il réduit les risques d'erreurs en fournissant des lignes directrices claires.
Ce type de CoT est aussi pertinent lorsque l'on connait précisément les étapes à suivre pour résoudre la tâche en question.
Ces deux approches, Zero-shot et Few-shot, permettent de maximiser le potentiel du Chain-of-Thought en fonction des besoins spécifiques de l'utilisateur. Le Zero-shot est idéal pour tester la capacité d'un modèle à "innover", ou lorsque l'on ne connait pas de méthode spécifique à suivre.
Tandis que le Few-shot offre un cadre plus structuré, augmentant ainsi la précision et la cohérence des réponses.
En combinant ces variantes, il est possible d'obtenir des performances optimales dans des contextes variés, allant des tâches de compréhension de texte simples à des raisonnements complexes nécessitant une rigueur particulière.
Comparaison avec d'autres techniques de prompt engineering
Le Chain-of-Thought se distingue de plusieurs autres techniques de prompt engineering, telles que le "Tree of Thoughts" et le "Prompt Chaining", qui sont utilisées pour guider les modèles de langage à travers des tâches complexes.
Ces méthodes partagent certaines similitudes avec le CoT mais se différencient par leur structure et leur manière de guider le raisonnement du modèle.
Tree of Thoughts
Le "Tree of Thoughts" est une technique où le raisonnement est structuré sous la forme d'un arbre, permettant ainsi au modèle de suivre plusieurs chemins de réflexion parallèles avant de converger vers une solution optimale.
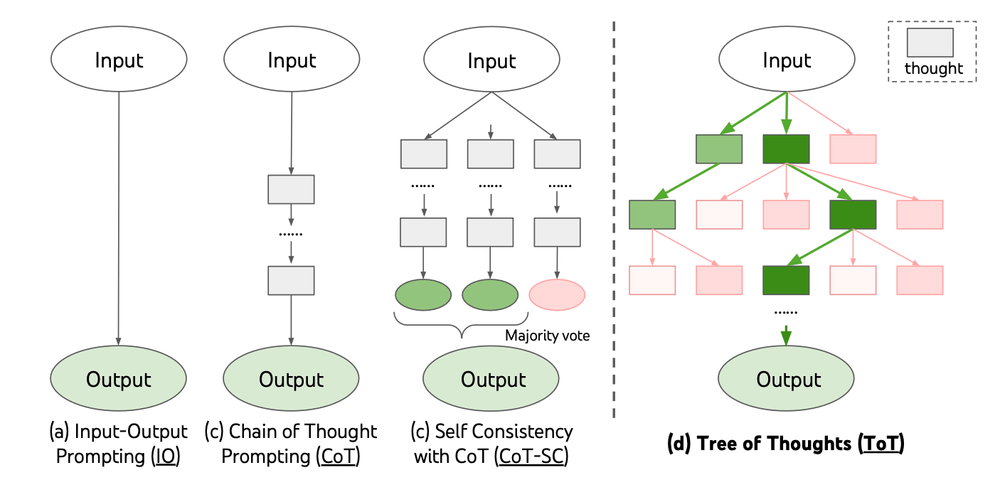
Contrairement au Chain-of-Thought, qui impose une séquence linéaire d'étapes, le Tree of Thoughts permet de bifurquer, de revenir en arrière, et d'explorer des alternatives avant de choisir la meilleure approche. Cela en fait une méthode très puissante pour les tâches où plusieurs solutions sont envisageables et où la comparaison entre différentes options peut améliorer la qualité des résultats.
L'inconvénient principal est qu'il peut être plus complexe à implémenter et exiger une plus grande capacité de calcul, en raison du nombre d'itérations potentielles.
Voici une vidéo qui illustre bien cette technique :
Prompt Chaining
Le "Prompt Chaining" consiste à diviser une tâche complexe en une série de prompts plus simples, qui sont liés les uns aux autres.
Chaque prompt génère une réponse qui est ensuite utilisée comme base pour le prompt suivant. Cette approche est particulièrement efficace pour les tâches qui peuvent être naturellement décomposées en sous-problèmes distincts.
Par exemple, pour une tâche de rédaction d'article, le premier prompt pourrait demander une introduction, le second pourrait se concentrer sur les points principaux, et un troisième sur la conclusion. Contrairement au Chain-of-Thought, où le raisonnement est explicité à l'intérieur d'un même prompt, le Prompt Chaining segmente le processus en plusieurs itérations successives, chacune dépendant des précédentes. Cela permet un contrôle plus fin à chaque étape, mais peut également rendre la progression plus fragmentée et nécessiter davantage de supervision de la part de l'utilisateur.
Comparaison des Avantages et Limites
Linearité vs Arborescence : Le Chain-of-Thought au même titre que le Prompt Chaining est linéaire. Chaque étape en découle de la précédente, tandis que le Tree of Thoughts permet une exploration arborescente, ce qui offre plus de flexibilité sur les réponses possibles (output). Mais sa mise en place peut être complexe.
Transparence : Le Chain-of-Thought offre un vrai avantage grâce à la transparence du raisonnement, car chaque étape est accessible. Ce qui n'est pas toujours le cas avec le Tree of Thoughts, où des branches entières peuvent être abandonnées.
Raisonnement : Le Prompt Chaining permet une segmentation très fine du processus, ce qui est utile pour des projets longs et "décomposables" en sous-tâches successives.
Cependant, cette méthode est peu efficace pour des demandes nécessitant un raisonnement plus poussé. Contrairement aux deux autres types.
Applications Pratiques du Chain-of-Thought
Le Chain-of-Thought peut être appliqué dans divers contextes pour maximiser la valeur des réponses fournies par les modèles de langage. Voici des exemples concrets :
1. Apprentissage
Dans le cadre de l'éducation, le Chain-of-Thought est extrêmement utile pour aider les étudiants à comprendre des concepts complexes.
Prenons, par exemple, l'apprentissage des mathématiques. Au lieu de simplement donner la réponse à un problème d'algèbre ou de physique, l'IA décompose le processus en plusieurs étapes, détaillant les calculs nécessaires, expliquant chaque formule et les raisons derrière chaque choix. Cela aide les élèves à non seulement connaître la réponse, mais aussi à comprendre le raisonnement logique qui les y mène.
Prenons un exemple mathématique simple comme l'addition de nombres entiers.
Si l'on demande à un enfant de trouver la somme de 23 + 45. Plutôt que de lui donner directement la réponse, le modèle d'IA utilisant le Chain-of-Thought décomposerait le calcul en plusieurs étapes :
- Additionner les dizaines : 20 + 40 = 60
- Additionner les unités : 3 + 5 = 8
- Combiner les résultats : 60 + 8 = 68
Cette approche permet à l'enfant de comprendre le raisonnement derrière l'addition, renforçant ainsi sa compréhension des concepts de base du calcul. Elle rend le processus plus explicite et logique, facilitant l'apprentissage des principes mathématiques fondamentaux.
2. Recherche Scientifique
Le Chain-of-Thought est aussi bénéfique en recherche scientifique, où il est essentiel de garder une traçabilité et une rigueur dans les méthodes.
Par exemple, dans le cadre de l'analyse de données d'une expérience en biologie, un chercheur pourrait utiliser cette approche pour structurer chaque étape de l'analyse des données. D'abord, le modèle pourrait aider à nettoyer les données, puis identifier des anomalies, et enfin appliquer des méthodes statistiques adaptées.
Supposons que des scientifiques étudient l'effet d'un nouveau traitement médicamenteux. Le modèle pourrait décomposer l'expérience en étapes claires :
- Collecte des échantillons
- Analyse statistique
- Tests de significativité
- Conclusions.
Cette capacité de décomposition structurée garantit que chaque partie du processus soit correctement documentée et interprétée, réduisant les risques d'erreurs et favorisant une meilleure reproductibilité des résultats.
3. Diagnostic Médical
En médecine, le Chain-of-Thought permet d'améliorer le processus de diagnostic en guidant le raisonnement clinique des professionnels de santé. Prenons le cas d'un patient présentant des symptômes variés, tels que la fièvre, des maux de tête et des éruptions cutanées.
Le modèle, en utilisant le Chain-of-Thought, décomposerait le raisonnement médical comme suit : premièrement, il identifierait les symptômes primaires ; ensuite, il ferait un tri parmi les diagnostics potentiels en éliminant ceux qui sont improbables ; et enfin, il proposerait une liste de diagnostics potentiels hiérarchisés par pertinence.
En suivant cette approche, le médecin peut examiner chaque étape et s'assurer que toutes les possibilités ont été considérées avant de choisir le traitement le plus approprié. Cette décomposition permet de renforcer la transparence et de réduire le risque de diagnostic erroné, en particulier dans des cas complexes.
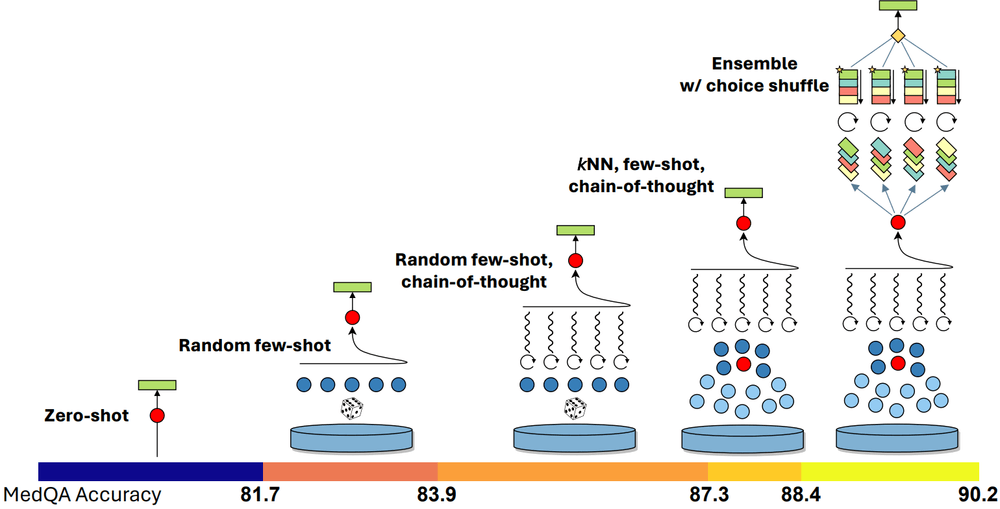
Le modèle GPT-4 Medprompt illustre bien ce potentiel. Cette IA a atteint une précision de 90,2 % sur des benchmarks médicaux !
4. Service Client et Support Technique
Dans le domaine du support client, le Chain-of-Thought permet de rationaliser le dépannage en guidant l'utilisateur à travers une série d'étapes claires. Par exemple, si un client rencontre des problèmes pour se connecter à sa box Internet, l'IA pourrait le guider en séquence : vérifier d'abord la connexion internet, puis vérifier les identifiants de connexion, et ensuite examiner les paramètres du navigateur.
Cette approche séquentielle réduit le nombre d'erreurs potentielles en s'assurant que chaque étape du processus est correctement suivie avant de passer à la suivante. Cela améliore l'expérience utilisateur et permet au support client de résoudre plus efficacement des problèmes répétitifs sans intervention humaine directe. Les agents humains pourront alors se concentrer sur des problèmes plus complexes.
5. Marketing et Analyse des Comportements
En marketing, le Chain-of-Thought est utilisé pour analyser le parcours du client, en décomposant chaque étape de l'interaction avec le produit.
Par exemple, l'IA pourrait examiner comment un consommateur découvre un produit, quelles sont les options qu'il considère, quels facteurs influencent sa décision d'achat, et comment il perçoit le produit après l'avoir utilisé.
En détaillant chaque phase du parcours de l'utilisateur, les spécialistes du marketing peuvent identifier précisément les points de friction (comme l'hésitation due au prix ou au manque de confiance) et adapter leurs stratégies pour surmonter ces obstacles.
De plus, cette analyse permet d'anticiper les comportements futurs des clients, d'améliorer la personnalisation des campagnes publicitaires et d'augmenter le taux de conversion.
Bonnes Pratiques pour utiliser le Chain-of-Thought
Pour tirer le meilleur parti du Chain-of-Thought, voici quelques bonnes pratiques pour maximiser la qualité des résultats générés par les modèles d'IA :
1. Bien Formuler les Prompts
Le succès du Chain-of-Thought repose largement sur la formulation des prompts. Un bon prompt doit être clair, précis, et guider le modèle à travers un raisonnement structuré.
Par exemple, lorsque vous demandez une explication, utilisez des termes qui incitent le modèle à décomposer chaque étape : "Explique en détail comment..." ou "Décompose les étapes nécessaires pour...". Cela pousse le modèle à produire une réponse plus organisée.
2. Commencer Simplement et Ajouter de la Complexité
Lorsque vous utilisez le Chain-of-Thought, commencez par des prompts simples qui peuvent être étendus progressivement. Cette approche permet au modèle de s'engager initialement avec des tâches moins complexes, facilitant ainsi la compréhension et l'adaptation du modèle aux étapes successives plus difficiles.
Cela permet aussi de maintenir le cone
3. Fournir des Exemples Guidés (Few-shot)
Lorsque cela est possible, fournissez au modèle des exemples similaires au problème que vous voulez résoudre. C'est ce que l'on a évoqué précédemment avec le "Few-shot Chain of Thought".
Par exemple, si vous souhaitez qu'un modèle effectue une analyse financière, commencez par un exemple bien balisé, montrant chaque étape de la méthode. Les exemples concrets, même peu nombreux, permettent au modèle de s'inspirer de la logique précédemment utilisée.
4. Vérifier et Réviser les Étapes
Étant donné que les erreurs dans une étape peuvent affecter tout le processus, il est essentiel de vérifier chacune des étapes du raisonnement.
Revoyez les réponses produites, en particulier pour les questions complexes, afin de détecter et corriger toute incohérence dès les premières étapes. Cette supervision garantit la qualité et la cohérence du raisonnement global.
5. Contextualiser le Raisonnement
Pour améliorer la cohérence des réponses du modèle, il est utile de maintenir un contexte clair tout au long du processus. Par exemple, si le modèle doit répondre à plusieurs questions liées entre elles, assurez-vous que chaque étape renforce les précédentes.
Cela est particulièrement pertinent pour des analyses longues, comme dans le diagnostic médical ou la recherche scientifique.
6. Limiter la Longueur des Chaînes
Une chaîne de raisonnement trop longue augmente le risque de perte de cohérence et d'erreurs cumulatives. Si le problème à résoudre est complexe, il peut être utile de le décomposer en plusieurs chaînes de raisonnements distinctes, puis de combiner les résultats à la fin.
Cette approche modulaire permet une meilleure gestion de chaque sous-problème tout en réduisant les risques liés à la longueur excessive.
7. Exploiter la Rétroaction Humaine
L'utilisation du Chain-of-Thought dans des environnements où des erreurs peuvent avoir de graves conséquences (comme en médecine) nécessite une validation humaine.
Encouragez une interaction humaine pour vérifier la justesse des résultats, et utilisez ce feedback pour ajuster la formulation des prompts. Cela permet d'améliorer continuellement la qualité des réponses générées.
Limites et Défis du Chain-of-Thought
Bien que le Chain-of-Thought présente de nombreux avantages, il comporte également quelques limites et des défis qu'il est essentiel de prendre en compte. Voici quelques-unes des principales contraintes associées à cette approche :
1. Augmentation du Temps de Calcul
L'une des limitations majeures du Chain-of-Thought est l'augmentation du temps de traitement requis pour générer une réponse. En décomposant chaque problème en plusieurs étapes successives, le coût en ressources de calcul devient plus élevé par rapport à une réponse directe.
Il suffit pour cela de voir le fonctionnement du modèle GPT-o1 :
Ce surcoût peut être problématique, notamment dans des applications où la rapidité est cruciale, par exemple en temps réel ou dans des systèmes à ressources limitées. Cela nécessite de trouver un équilibre entre précision et efficacité.
2. Complexité de la Création de Prompts
L'efficacité du Chain-of-Thought repose largement sur la formulation des prompts. La création de prompts adaptés qui permettent un raisonnement optimal n'est pas toujours triviale ; elle demande de l'expérience et une compréhension approfondie du problème à résoudre.
Une formulation incorrecte ou "simpliste" peut conduire à des réponses inexactes ou incohérentes, ce qui limite l'utilité de cette approche. De plus, pour garantir la qualité des prompts, une intervention humaine est souvent nécessaire, ce qui augmente la charge de travail et le temps de développement.
3. Amplification des Biais
En raison de la nature séquentielle du Chain-of-Thought, les biais qui apparaissent au début de la chaîne de raisonnement peuvent être amplifiés au fur et à mesure des étapes. Si le modèle commet une erreur initiale, cette dernière peut impacter tout le raisonnement suivant et mener à une conclusion erronée.
Par exemple, si une hypothèse incorrecte est posée lors de la première étape, cette hypothèse sera utilisée tout au long du processus, affectant l’ensemble des résultats. La supervision humaine et la révision des étapes initiales sont donc indispensables pour atténuer ce problème.
4. Difficultés de Maintien du Contexte
Les modèles de langage, même lorsqu'ils utilisent le Chain-of-Thought, ont parfois du mal à maintenir une cohérence contextuelle sur une longue chaîne de raisonnement. Plus une tâche est complexe et nécessite de nombreuses étapes, plus le risque d'"oublier" certaines informations critiques augmente.
Cela peut mener à des erreurs ou à des conclusions incomplètes. Cette limite est particulièrement présente lorsque les chaînes de réflexion deviennent longues et complexes, car le modèle peut "perdre le fil" des informations initiales.
5. Problèmes de Scalabilité
Lorsque les tâches deviennent très complexes et nécessitent de nombreuses étapes, le Chain-of-Thought peut devenir difficile à gérer.
Plus la chaîne de raisonnement est longue, plus le risque d’erreurs cumulatives est élevé, et plus le temps de calcul s’allonge. Par ailleurs, cette complexité accrue peut rendre l’interprétation des résultats plus difficile, surtout pour des utilisateurs qui ne sont pas experts. Cela nécessite de rendre les explications intermédiaires claires et de simplifier autant que possible la logique, tout en maintenant l’exactitude des réponses.
La solution sera de ne pas fournir une problématique trop complexe dès la première requête. Mais de faire un premier travail de décomposition du problème à résoudre, comme indiqué précedemment dans les bonnes pratiques.
6. Besoin d'une Supervision Humaine
Malgré les améliorations que le Chain-of-Thought apporte en termes de transparence et de logique, une supervision humaine reste souvent nécessaire pour vérifier la justesse des réponses fournies par le modèle. Cette supervision est cruciale, surtout dans des domaines critiques comme la médecine ou la recherche scientifique, où une erreur pourrait avoir des conséquences graves. La vérification humaine permet de s'assurer que chaque étape de la chaîne de raisonnement est correcte et cohérente.
Malgré ses limites actuelles, la méthode du CoT est puissante. Elle peut constituer une aide précieuse pour votre stratégie de Growth Marketing Durable. N'hésitez pas à me contacter sur LinkedIn pour échanger davantage sur le sujet.